
The Impact of Agentic AI on the Voice Pipeline: How Voicebot Assurance Must Evolve
Voicebot deployment has accelerated in the CX space over the last 12-24 months. A recent industry index indicates that 78% of businesses surveyed have already deployed or are actively piloting a voice AI solution, up from 45% just two years ago.
Most of these businesses believe their pre-launch testing is sufficient to prevent voicebot failures and risk exposure. The reality? There’s a good chance most are wrong.
What Makes AI Voice Agent Testing So Difficult?
Voicebot interactions are not a single system. They are a multi-stage pipeline.
To put it simply, these interactions move through a connected sequence of specialized systems, each responsible for a distinct function.
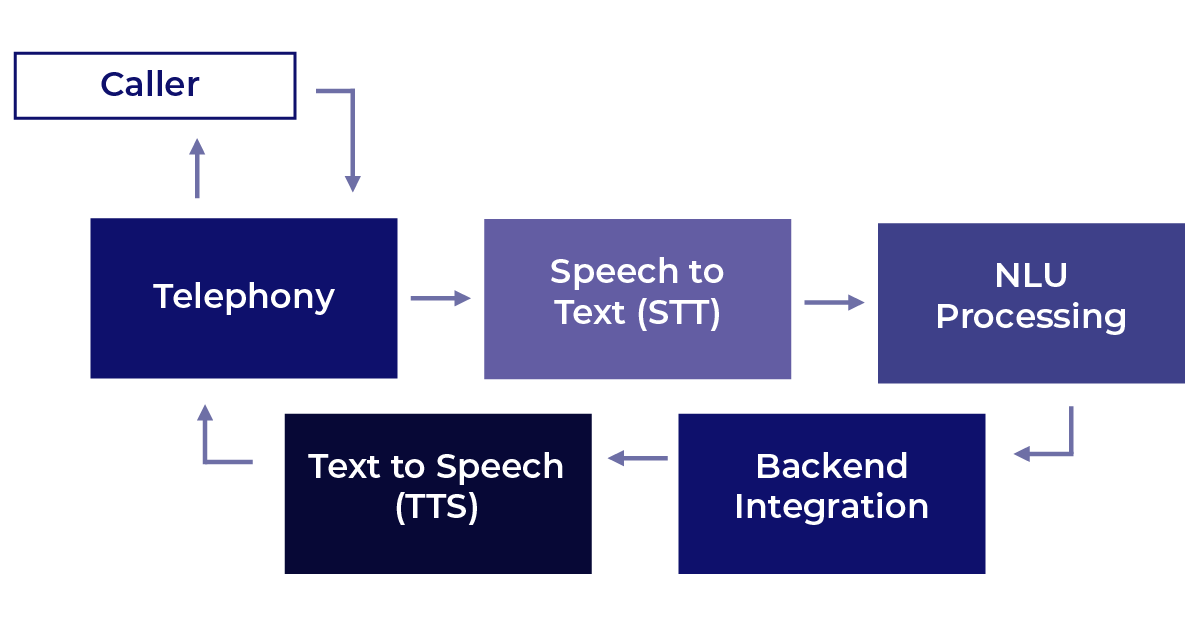
When a caller connects, the telephony layer receives the call and passes the audio to a speech-to-text engine, which converts spoken words into text. That text is then interpreted by natural language understanding (NLU) processing, which determines intent and drives the appropriate response logic. The NLU layer reaches into backend systems to retrieve or act on relevant data, then hands off the output to a text-to-speech engine, which converts the response back into audio. The call then returns through the telephony layer to complete the exchange with the caller.
Five stages, five opportunities for failure. And each one can undermine a response that was otherwise correct.
What this means in practice is that your voice AI is only as reliable as its weakest stage. A flawless NLU response is meaningless if STT mishears the customer, if updated product information is not available to the bot, if TTS mispronounces a product name, or if latency degrades the perceived quality of the interaction.
AI adds an additional dimension: probabilistic behavior. Unlike deterministic, rule-based systems, AI does not produce the same output for the same input every time. This is precisely what makes AI harder to test. An LLM validated at launch can drift when subjected to live volumes, real accents, background noises, and edge-case prompts. Add in continuously changing data, rules and guardrails and the risk of deploying an untested agentic system should produce many sleepless nights.
The Gaps that Traditional CX Assurance Platforms Leave Open
Many enterprises are still relying on tools and processes that were not designed for this kind of system. When you introduce an LLM into the voice pipeline, you introduce probabilistic behavior, continuous model drift, and open-ended decision-making that conventional testing tools were never designed to evaluate. The result is a set of structural gaps that many traditional CX assurance and testing tools miss.
The text-only gap
Most LLM evaluation tools (DeepEval, RAGAS, Langfuse) assess the text layer only. They cannot test what the customer actually hears across the full LLM voice pipeline.
The pre-launch gap
Pre-launch testing validates a system at a single point in time, under controlled conditions, against a known set of inputs. Production is none of those things. Forrester warned in its 2026 predictions that one-third of companies will damage customer trust by deploying AI prematurely, before it has been adequately validated for the conditions it will actually face. The gap between what was tested and what customers experience is where CX breaks down.
The drift gap
The reality is that AI models, once deployed into production, degrade under real-world conditions: accent diversity, barge-in interruptions, concurrent load, and evolving customer language. Agentic testing must account for these variables continuously, not just at release.
The coverage gap
CX monitoring tells you something is broken. It does not tell you whether your agentic AI system is escalating correctly, staying on policy, or handling edge cases your team didn't anticipate. That distinction is the difference between observation and contact center AI assurance.
What True Agentic Assurance Requires
True agentic AI assurance requires synthetic customer simulation across the full voice pipeline. Not component checks, but end-to-end journey validation under real-world conditions. Breadth and depth are both required of CX assurance.
That means AI voice agent testing must include diverse accents, background noise, DTMF (dual-tone multi-frequency) fallback, barge-in handling, and concurrent call load at scale.
AI behavior needs to be validated continuously after release, as well as after every model update, configuration change, or platform upgrade.
This means continuously validating:
intent recognition
escalation logic
policy adherence
tone and sentiment
Contact center AI assurance also needs to be able to generate a governance record. When a regulator, auditor, or board asks what was tested and when, the actual answer must be documented.
The Governance Dimension, and What Boards Want to See
Voice AI decisions are now driven more by enterprise risk than technical capabilities. Courts have established that enterprises are liable for what their AI says, with the 2024 Air Canada case being the most commonly cited precedent. As of 2026, there are 58 active AI chatbot lawsuits moving through the courts.
Boards and risk committees are beginning to ask whether AI governance has kept pace with AI deployment. "We ran a test before launch" is not an acceptable answer at the governance level.
When a board is asking that question, the answer they need is not a description of what was done before launch. They need a record that is timestamped, continuous, and defensible under scrutiny. And this is precisely what regulators are starting to require. The EU AI Act, as well as 78 current state-level bills in the US, are creating a documentation expectation that episodic pre-launch testing cannot satisfy.
The enterprise that cannot produce a continuous, audit-ready record of how its voice AI behaves is carrying undocumented risk.
A Framework for Evaluating Your Current Coverage
When reviewing your agentic assurance plans, these are the questions that matter:
Can you test the full voice pipeline — telephony through the AI and back as a single interaction?
Are you validating agentic AI behavior in production, or only in pre-launch test environments?
Do you have continuous agentic testing coverage across model updates and configuration changes, or only point-in-time snapshots?
Can you produce a timestamped audit record of AI behavior across every validation cycle?
Are you simulating real-world conditions including accent variation, concurrent load, edge-case prompts, guardrail validation and hallucination prevention?
Functional testing confirms behavior at a specific point in time. Monitoring confirms something is happening. Agentic assurance confirms it continuously, in production, at scale.